
Least squares regressions#
Finnish university students are encouraged to use the CSC Notebooks platform.
Others can follow the lesson and fill in their student notebooks using Binder.
![]()
Least squares regressions are a common way of determining whether two values are linearly related to one an other. In other words, this is a method to determine whether a line is a good “fit” to some measured values. Not all data should be expected to be fit well by a line, but linear regressions are a powerful method for determining cases when two variables are directly related to one another. A common example might be the temperature at which magma erupts versus the SiO2 content of the magma, as shown below in Figure 2.1.
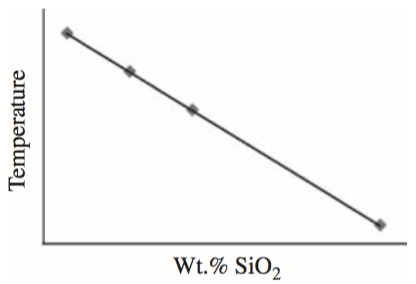
Figure 2.1. Eruption temperatures of magmas as a function of their SiO2 content with a linear regression line. Source: Figure 16.1 from McKillup and Dyar, 2010.
The general idea with calculating a linear regression is that we want to find the equation of a line that best fits some $x$-$y$ data, such as temperature and SiO2 content in the example above. To do this, we first need to recall the equation for a line:
$$ \large y = A + B x $$ where $x$ and $y$ are the coordinates of the data points, $A$ is the $y$-intercept, and $B$ is the slope of the line.
Thus, in order to calculate a “best fit” line to some data, we will need to determine the values of the constants $A$ and $B$. Consider the example below in which $A$ and $B$ are known. If we make the rather common assumption that the uncertainties for the values on the $x$ axis are negligible compared to the uncertainties along the $y$ axis, we can say:
$$ \large (\mathrm{true~value~of~}y_{i}) = A + B x_{i} $$
Thus, it is possible to find the value of $y$ for two linearly related values when $A$ and $B$ are known.
Finding the values of $A$ and $B$ then for the case of a linear regression to some $x$-$y$ data is fairly straightforward, though it does involve a bit of algebra. For our purposes, I’ll refer you to Chapter 8 of Taylor, 1997 for a complete explanation of how to find $A$ and $B$, and simply present the relevant equations below. The value of the $y$-intercept can be found using
$$ \large A = \frac{\sum{x^{2}} \sum{y} - \sum{x} \sum{xy}}{\Delta} $$
where $x$ is the $i$th data point plotted on the $x$-axis, $y$ is the $i$th data point plotted on the $y$-axis, and $\Delta$ is defined below.
The line slope can be found using
$$ \large B = \frac{N \sum{xy} - \sum{x} \sum {y}}{\Delta} $$
where $N$ is the number of values in the regression.
And the value of $\Delta$ is
$$ \large \Delta = N \sum{x^{2}} - \left( \sum{x} \right)^{2} $$
With the equations above, you are now able to calculate unweighted regression lines, the best-fit lines to some $x$-$y$ data in which the uncertainties in the measurements are not considered to influence the fit of the line. It is also possible to fit regression lines that consider the variable uncertainties in the data, referred to as weighted regressions, but will will not consider that type of regression for the time being.
In-class demonstration space#
The cell below can be used for following live demonstrations during the class lesson.
# Coding done during class time goes below
# Import the libraries we need
import numpy as np
import matplotlib.pyplot as plt
# Create NumPy arrays with our toy dataset
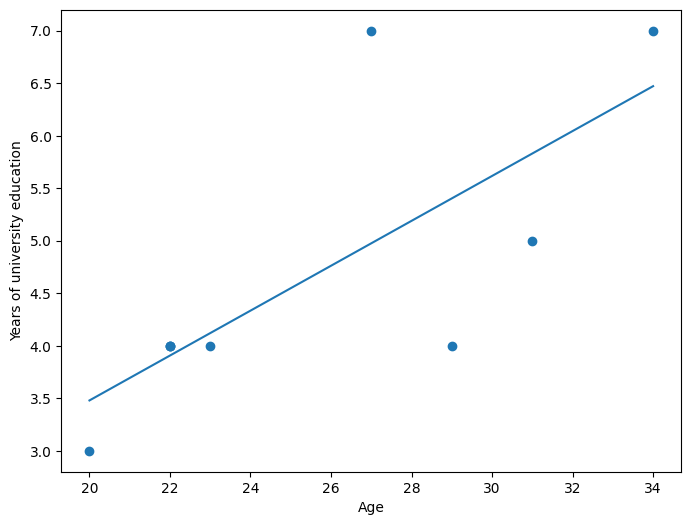
ages = np.array([34, 22, 22, 27, 31, 29, 22, 23, 20])
years_of_univ = np.array([7, 4, 4, 7, 5, 4, 4, 4, 3])
# Calculate our slope and y-intercept
delta = len(ages) * (ages**2).sum() - (ages.sum())**2
a = (((ages**2).sum() * years_of_univ.sum()) - (ages.sum() * (ages * years_of_univ).sum())) / delta
b = ((len(ages) * (ages * years_of_univ).sum()) - (ages.sum() * years_of_univ.sum())) / delta
print(f"Slope: {b}")
Slope: 0.21378504672897197
print(f"Intercept: {a}")
Intercept: -0.7967289719626168
# Create figure and axes
fig, ax = plt.subplots(1, 1, figsize=(8, 6))
# Plot data
ax.scatter(ages, years_of_univ)
ax.plot([ages.min(), ages.max()], [a + b * ages.min(), a + b * ages.max()])
ax.set_xlabel('Age')
ax.set_ylabel('Years of university education')
ax.text(28, 3, f"Correlation coefficient: {r:.2f}")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[6], line 9
7 ax.set_xlabel('Age')
8 ax.set_ylabel('Years of university education')
----> 9 ax.text(28, 3, f"Correlation coefficient: {r:.2f}")
NameError: name 'r' is not defined
$$ \large r = \frac{\sum{\left(x_{i} - \bar{x} \right)\left(y_{i} - \bar{y} \right)}}{\sqrt{\sum{\left(x_{i} - \bar{x} \right)^2} \sum{\left(y_{i} - \bar{y} \right)^2}}}, $$
# Initialize our summing variables
topsum = 0
bottomsumx = 0
bottomsumy = 0
# Calculate our top and bottom sums
for i in range(len(ages)):
topsum = topsum + (ages[i] - ages.mean()) * (years_of_univ[i] - years_of_univ.mean())
bottomsumx = bottomsumx + (ages[i] - ages.mean())**2
bottomsumy = bottomsumy + (years_of_univ[i] - years_of_univ.mean())**2
# Calculate r
r = topsum / np.sqrt(bottomsumx * bottomsumy)
# Print out result
print(f"Correlation coefficient: {r:.2f}")
Correlation coefficient: 0.74